Currently, AI plays an important role in image recognition because of its outstanding performance of CNN (convolution neural network) algorithm. The basic CNN algorithm requires a lot of computation and data reuse, which is very suitable for implementation with FPGA. Last month, Ralph WitTIg (Xilinx CTO Office's Distinguished Engineer) delivered a 20-minute speech at the 2016 OpenPower Summit and discussed some of the results of CNN studies at Chinese universities including Tsinghua University.
In this study, several interesting conclusions related to the energy consumption of the CNN algorithm have emerged:
1 limited use of on-chip Memory;
2 use a smaller multiplier;
3 Perform fixed-point matching: Reduce the accuracy of the fixed-point calculation result to 16 bits with respect to 32-bit fixed-point or floating-point calculation. If dynamic quantization is used, 8-bit calculations can also produce good results.
In the speech, WitTIg also mentioned two products related to CNN: CAPI-compaTIble Alpha DataADM-PCIE-8K5 PCIe accelerator card and AuvizDNN (Deep Neural Network) development library provided by Auviz Systems.
ADM-PCIE-8K5 PCIe Accelerator Card
The Alpha DataADM-PCIE-8K5 PCIe Accelerator Card is used for X86 and IBM Power8/9 data center and cloud services. The accelerator card is based on the Xilinx Kintex UltraScale KU115 FPGA and supports Xilinx SDAcess OpenCL, C/C++ based development and Vivado HLx based HDL. HLS design process.

Figure 1 Alpha DataADM-PCIE-8K5 PCIe Accelerator Card
Alpha DataADM-PCIE-8K5 PCIe acceleration card with 32GB DDR4-2400 memory (16GB with ECC), dual channel SFP+ supports dual 10G Ethernet access. Design resources such as board-level support package (BSP) including high-performance PCIe/DMA, CAPI for OpenPOWER architecture, FPGA reference design, plug-and-play O/S driver, and mature API are available.
AuvizDNN development library
Deep learning techniques use a large amount of known data to find a set of weights and offset values ​​to match the expected results. The fact that processing is called training and the result of training is a large number of models has prompted engineers to seek specialized hardware such as GPUs for training and classification calculations.
With the huge increase in the amount of data in the future, machine learning will be moved to the cloud to complete. In this case, there is an urgent need for a processing platform that can speed up the algorithm without increasing power consumption on a large scale. In this case, the FPGA begins to debut.
As some of the advanced development environments are put into use, software development engineers have made their designs easier to implement on Xilinx FPGAs. The AuvizDNN library developed by Auviz Systems provides users with an optimized function interface that allows users to create custom CNNs for different applications. These functions can be easily invoked through an integrated development environment such as Xilinx SDAcess. After the object and data pool are created, the function is called to create each convolutional layer, then the dense layer, and finally the softmax layer, as shown in Figure 2 below.
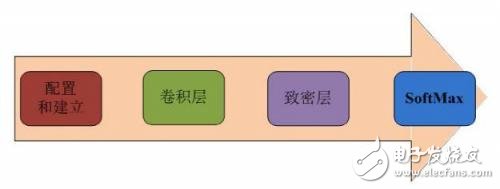
Figure 2 implements CNN function call sequence
24V Frequency Transformer,110V 60Hz To 220V 50Hz Transformer,Oil-Filled Electric Transformer, electronic oiled transformer
IHUA INDUSTRIES CO.,LTD. , https://www.ihuagroup.com