The so-called request merging refers to the process of merging multiple IO requests that are consecutive in physical addresses between processes or processes into a single IO request, thereby improving the processing efficiency of IO requests. In the previous series of articles on general block layer introduction, we mentioned the concept of IO request merging more or less. In this paper, we concentrate on combing IO requests in the block layer from the beginning to enhance the understanding of IO request merging. . First look at a picture. The following figure shows the IO request data generated by the user process, the final persistent storage to the physical storage medium, the data flow experienced in the kernel space and possible trigger points merging IO requests.
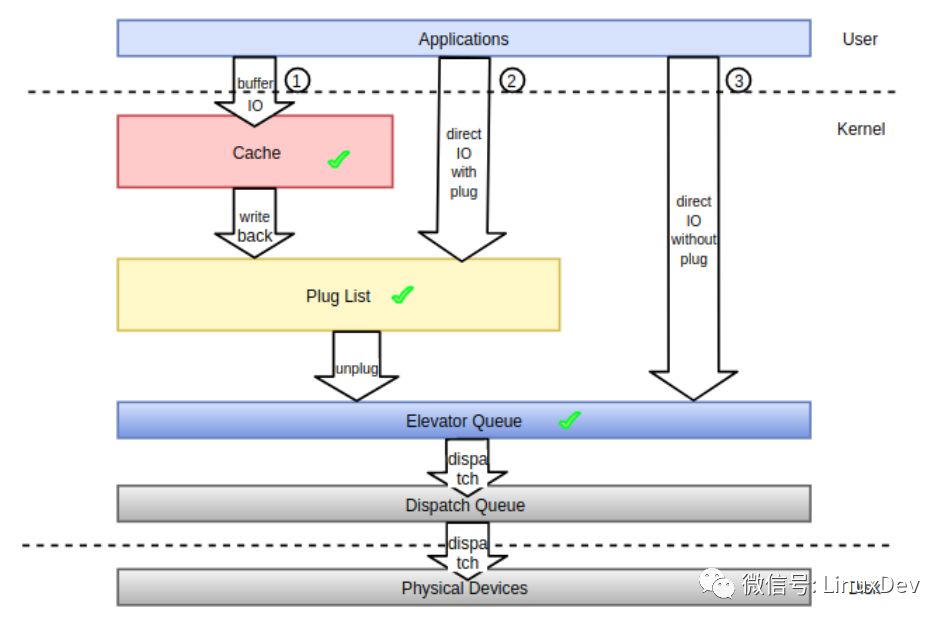
From the kernel point of view, the IO path generated by the process mainly has three of the following:
1 Cache IO, Corresponding to path 1 in the figure, most of the IO in the system takes this form, making full use of the advantages brought by the page cache of the filesystem layer. The IO generated by the application program falls into the page cache after the system call. Can be directly returned, cached data in the page cache by the kernel write-back thread at the appropriate timing is responsible for synchronization to the underlying storage medium, of course, the application can also initiate a write-back process (such as the fsync system call) to ensure that the data is synchronized as soon as possible On the storage medium, to avoid system crashes or data inconsistency caused by power down. Caching IO can bring a lot of benefits. First, the application returns the IO to the page cache and returns directly. This avoids the IO protocol stack from going through the IO protocol every time, which reduces the latency of the IO. Secondly, the cache in the page cache is written back in pages or blocks. It is not that the application submits several IOs to the page cache. When writing back, it needs to submit several IOs to the common block layer. Pieces of IO requests that are discontinuous but spatially contiguous can be merged into the same cache page for processing. Again, if the IO generated before the application is already in the page cache, and subsequent generation of the same IO, then only the old IO in the page cache need to be overwritten by the IO, so if the application frequently operates the file At the same location, we only need to submit the last IO to the underlying storage device. Finally, the application writes the cache data in the page cache to serve the subsequent read operation. When reading the data, it first searches the page cache. If it hits, it will directly return. If it is missed, it will be read from the bottom and saved to the page. In the cache, you can hit from the page cache the next time you read.
2 Non-cached IO (with storage), corresponding to path 2 in the figure, this type of IO bypasses the file system layer cache. The user needs to add the "O_DIRECT" flag when opening a file to be read or written, which means direct IO and does not involve the file system's page cache. From the user's point of view, the IO form that the application can directly control, in addition to the above-mentioned "cache IO", the rest of the IO will take this form, even if the file is opened with the "O_SYNC" flag, the resulting IO will also enter the list of storage chains (Plug List in the figure). If the application has cached itself in user space, then this IO approach can be used, common as database applications.
3 non-caching IO (without storage), corresponding to the path 3 in the figure, the kernel general block layer storage mechanism only provides an interface to the kernel space to control the IO request is stored, the user space process has no way to control the submitted IO When the request enters the common block layer, it is stored. Strictly speaking, the IO generated directly in the user space will follow the storage path. Even if it is IO, the “O_DIRECT†and “O_SYNC†flags are attached (refer to the “Linux generic block layer introduction (part1: bio layer)†Streaming chapter), the user indirectly generated IO, such as file system log data, metadata, some will not take the storage path but directly into the scheduling queue to get the schedule as soon as possible. It should be noted that general-purpose block-level storage only provides mechanisms and interfaces and does not provide tactics, as it does not require storage and when the storage is completely determined by the IO dispatcher in the kernel.
No matter which IO path is used in the application, the kernel will try its best to merge the IOs. The kernel sets three best attack points on the IO protocol stack to facilitate this merge:
l Cache
l Plug List
l Elevator Queue
Cache merge
IO is only IO data in the page cache of the file system layer. There is no IO request (bio or request). Only the page cache will generate IO requests when reading and writing. This article focuses on the IO request in the common block layer of the merger, so for the merger of the IO in the cache layer only to do the phenomenon analysis, do not go deep into the internal logic and code details. In the case of cached IO, write data submitted by the user process accumulates in the page cache. The basic unit of the cache to save IO data is page, the size is generally 4K, so the cache is also called "page cache", the small block data submitted by the user process can be cached to the same page in the cache, and the last writeback thread will be a page The data in the one-time submission to the general block layer processing. Write a raw device with the dd program as an example. Write 1K data at a time and write 16 times in succession:
Dd if=/dev/zero of=/dev/sdb bs=1k count=16
The observations made by blktrace are:
Blktrace -d /dev/sdb -o - | blkparse -i -
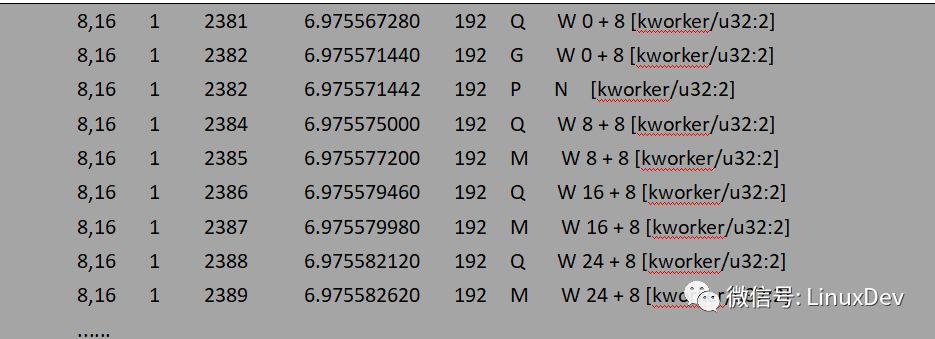
The processing of bio requests at the generic block level is mainly reflected by the sixth column. If you do not know much about the output of blkparse, you can use blktrace. Look at the output of each line to see how the application-generated write IO is dispatched to the generic block layer via the page cache:
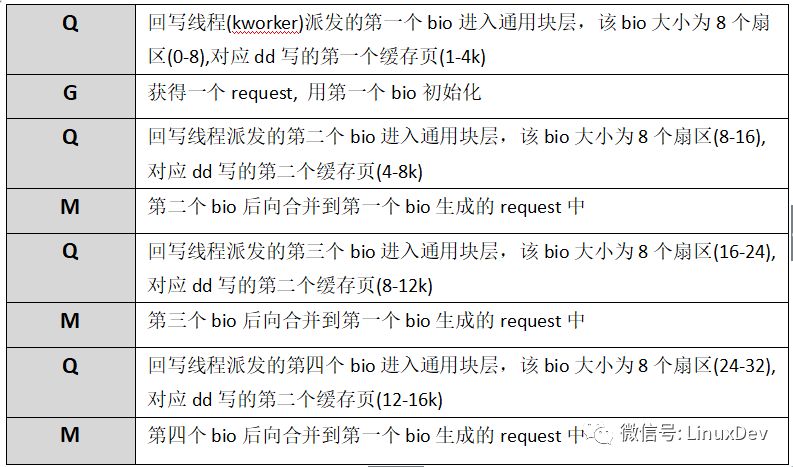
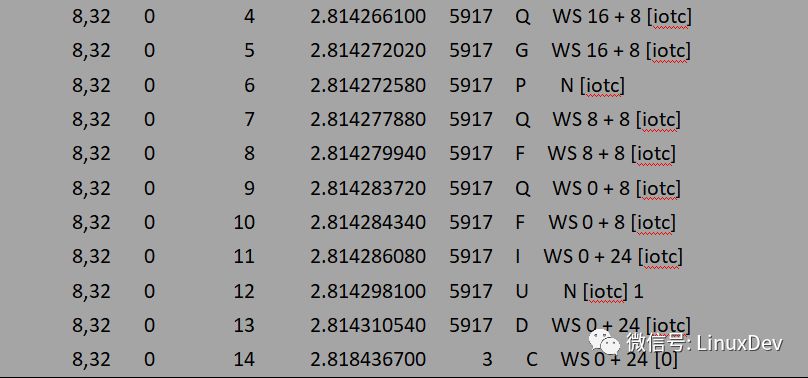
At this stage, we only pay attention to how the IO is dispatched from the page cache to the common block layer, so the downstream escaping and dispatching process is not posted. Write-back thread – The kworker dispatches 1K blocks read and written by the dd program to the general block layer processing in units of 8 sectors (sector size is 512B, 8 sectors is 4K corresponding to a page size). The dd program was written 16 times, the write-back thread only wrote 4 times (corresponding to four Qs), and the page cache caching function effectively combined the IO data directly generated by the application. The file system layer page cache also has a certain role in the read IO, read IO with a buffer will trigger the file system layer read-ahead mechanism, the so-called pre-reading has a special read-ahead algorithm, by determining the user process IO trend, advance the storage media The data block on the read into the page cache, the next read operation can be directly hit from the page cache, and does not need to initiate a read request to the block device each time. Or read a bare device with the dd program as an example, read 1K data each time, read 16 times in succession:
Dd if=/dev/sdb of=/dev/zero bs=1K count=16
The observations made by blktrace are:
Blktrace -d /dev/sdb -o - | blkparse -i -
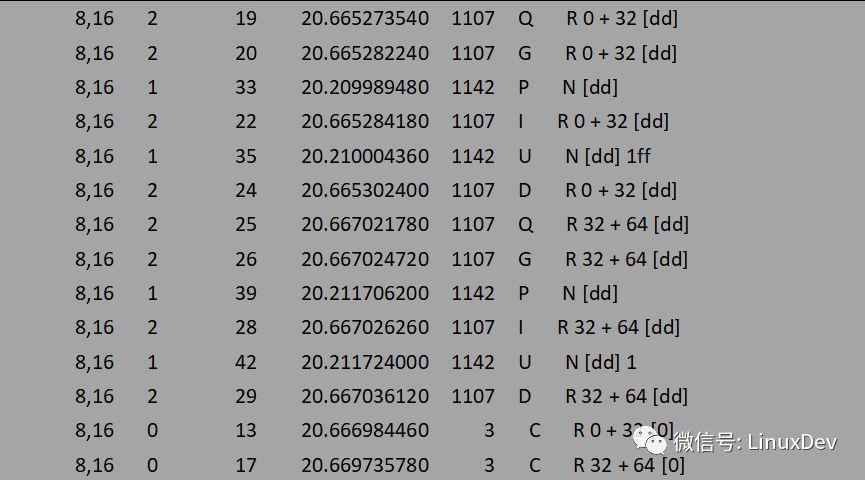
The same attention is only paid to how the IO is dispatched from the upper layer to the common block layer. The IO is not concerned with the specific situation at the common block layer. The P, I, U, D, and C operations are not considered first. Then the above output can be simply resolved as follows:
The read operation is synchronous, so the dd process itself triggers the read request. The dd process initiated 16 read operations and read a total of 16K data, but the read-ahead mechanism sent only two read requests to the bottom layer, which were 0+32 (16K), 32+64 (32K), and a total of 16 read ahead. + 32 = 48K data, and save it to the cache, more pre-read data can serve for subsequent read operations.
Plug merge
Before reading this section, you can first review the series of articles on bio and request in the linuxer public number, familiar with the IO request processing at the common block level, and the principle and interface of the plug-in mechanism. Specially recommended by Mr. Song Baohua, “BIO's Magnificent Life†written by Mr. Song Baohua, introduced the life cycle of a document io in an easy-to-understand manner.
Each process has a private storage chain list. If the process enables the storage function before sending the IO to the common block layer, the IO requests are stored in the storage chain list until they are sent to the IO scheduler. When (unplug) is delivered to the scheduler in batches. The main purpose of flow storage is to increase the chance of requesting a merger. Bio will attempt to merge with the request stored in the flow chain list before entering the flow chain list. The interface used is blk_attempt_plug_merge(). This article is based on the kernel 4.17 analysis, source code From 4.17-rc1.

The code traverses the request in the storage chain list, uses blk_try_merge to find a request that can be merged with bio, and determines the merge type. There are three types of merge types in the storage chain list: ELEVATOR_BACK_MERGE, ELEVATOR_FRONT_MERGE, and ELEVATOR_DISCARD_MERGE. Ordinary file IO operation will only perform the first two kinds of merges. The third one is the combination of discarding operations. It is not the common IO merging, so it is not discussed.
Bio backward merge (ELEVATOR_BACK_MERGE)
In order to verify various combinations of IO requests at the common block layer, the following test program is prepared. The test program uses an asynchronous IO engine that is natively supported by the kernel and can asynchronously submit multiple IO requests to the kernel at a time. In order to reduce the page cache and file system interference, O_DIRECT is used to distribute IO directly to the raw device.
Iotc.c
...
/* dispatch 3 4k-size ios using the io_type specified by user */
#define NUM_EVENTS 3
#define ALIGN_SIZE 4096
#define WR_SIZE 4096
Enum io_type {
SEQUENCE_IO,/* dispatch 3 ios: 0-4k(0+8), 4-8k(8+8), 8-12k(16+8) */
REVERSE_IO,/* dispatch 3 ios: 8-12k(16+8), 4-8k(8+8), 0-4k(0+8) */
INTERLEAVE_IO, /* dispatch 3 ios: 8-12k(16+8), 0-4k(0+8), 4-8k(8+8) */ ,
IO_TYPE_END
};
Int io_units[IO_TYPE_END][NUM_EVENTS] = {
{0, 1, 2},/* corresponding to SEQUENCE_IO */
{2, 1, 0},/* corresponding to REVERSE_IO */
{2, 0, 1}/* corresponding to INTERLEAVE_IO */
};
Char *io_opt = "srid:";/* acceptable options */
Int main(int argc, char *argv[])
{
Int fd;
Io_context_t ctx;
Struct timespec tms;
Struct io_event events[NUM_EVENTS];
Struct iocb iocbs[NUM_EVENTS],
*iocbp[NUM_EVENTS];
Int i, io_flag = -1;;
Void *buf;
Bool hit = false;
Char *dev = NULL, opt;
/* io_flag and dev got set according the the options passed by user, don't paste the code of parsing here to shrink space */
Fd = open(dev, O_RDWR | __O_DIRECT);
/* we can dispatch 32 IOs at 1 systemcall */
Ctx = 0;
Io_setup(32, &ctx);
Posix_memalign(&buf,ALIGN_SIZE,WR_SIZE);
/* prepare IO request according to io_type */
For (i = 0; i < NUM_EVENTS; iocbp[i] = iocbs + i, ++i)
Io_prep_pwrite(&iocbs[i], fd, buf, WR_SIZE, io_units[io_flag][i] * WR_SIZE);
/* submit IOs using io_submit systemcall */
Io_submit(ctx, NUM_EVENTS, iocbp);
/* get the IO result with a timeout of 1S*/
Tms.tv_sec = 1;
Tms.tv_nsec = 0;
Io_getevents(ctx, 1, NUM_EVENTS, events, &tms);
Return 0;
}
The test program receives two parameters, the first one acting as the device, the second as the IO type, defining three IO types: SEQUENCE_IO (sequential), REVERSE_IO (inverse), and INTERLEAVE_IO (alternate) to verify the reservoir phase, respectively The bio merge, forward merge, and request stream merge phases. In order to reduce the space, the source code posted here removes the option resolution and fault-tolerance processing and only keeps the trunk. The original version is located at: https://github.com/liuzhengyuan/iotc.
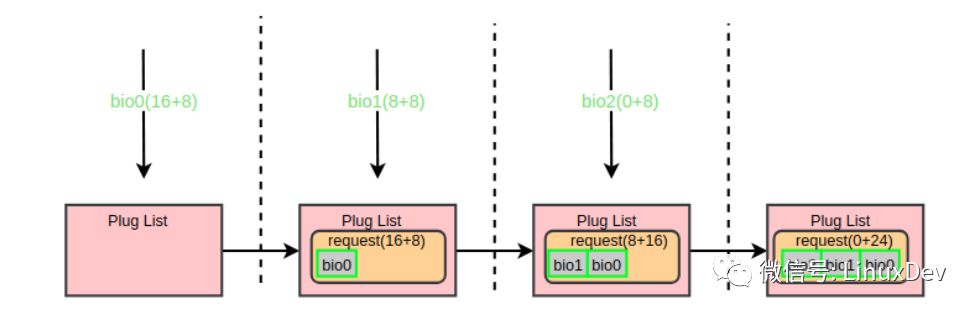
In order to verify the backward integration of bio in the storage phase, we use the above test procedure iotc to dispatch three write ios in sequence:
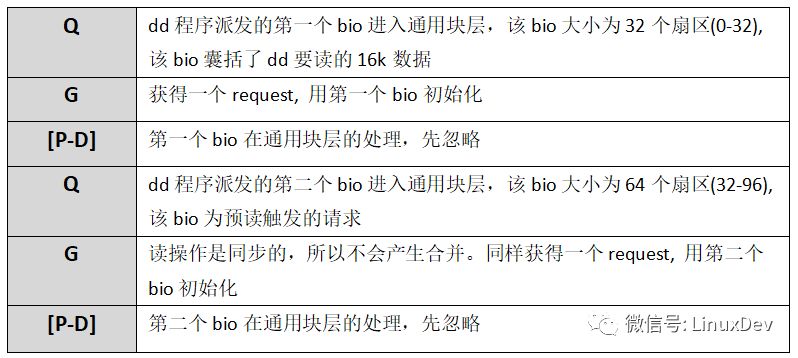
# ./iotc -d/dev/sdb -s
-d Specifies the device sdb to use, -s specifies that the IO mode is SEQUENCE_IO (order), which means that three write requests are initiated sequentially: bio0(0 + 8), bio1(8 + 8), bio2(16 + 8). Observe the merging of bio requests dispatched by iotc in the common block-level flow chaining list through blktrace:
Blktrace -d /dev/sdb -o - | blkparse -i -
The above output can simply be resolved as:

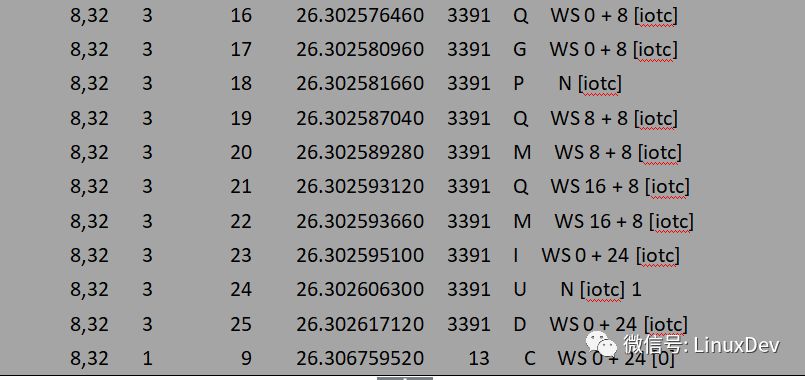
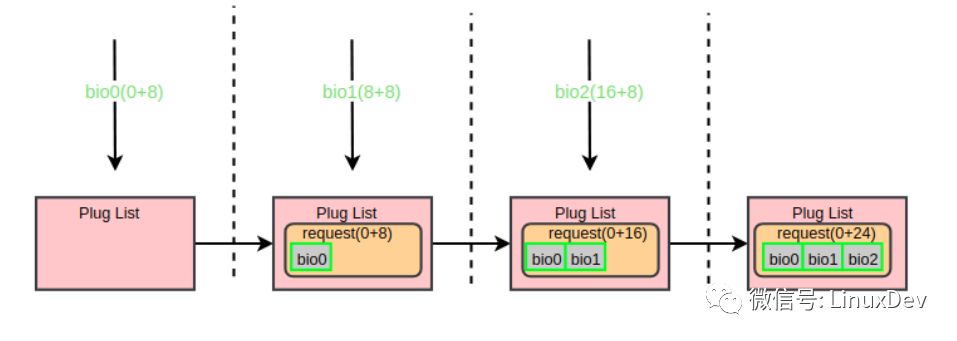
When the first bio (bio0) enters the common block layer, the current storage link list is empty, so a request is applied and initialized with bio0, and then the request is added into the flow chain list, and at the same time, the blktrace storage flow is officially notified. When the second bio (bio1) arrives, it will follow the logic of blk_attempt_plug_merge and try to call bio_attempt_back_merge to merge with the request in the flow chain table. It is found that it can be merged into the tail of the request of the first bio, and then returns directly. The third bio (bio2) process is the same as the second one. After the merging of the flow, the three IO requests are finally merged into one request (0 + 24). Use a diagram to show the entire consolidation process:
Bio forward merge (ELEVATOR_FRONT_MERGE)
To verify the forward merge of bio during the storage phase, use iotc to send three write ios in reverse:
# ./iotc -d/dev/sdb -r
-r Specifies the IO mode to be REVERSE_IO (reverse order), which means that three write requests are initiated in reverse order: bio0(16 + 8), bio1(8 + 8), bio2(0 + 8). The observation of blktrace is:
Blktrace -d /dev/sdb -o - | blkparse -i -
The above output can simply be resolved as:

Compared with the previous backward merge, the only difference is that the merge mode changes from the previous "M" to the current "F", that is, the bio_attempt_front_merge branch is taken in blk_attempt_plug_merge. The following diagram shows the forward merge process:
The "plug merge" will not do the advanced merge of request and request. The merge between the requests in the flow list will be done when the flow is released, ie in the "elevator merge" described below.
Elevator merge
The above-mentioned consolidation of the storage chain list serves the in-process IO requests. Each process only submits IO requests to its own storage chain table. The storage chain tables between the processes are independent and do not interfere with each other. However, multiple processes can initiate IO requests to a device at the same time, then the common block layer also needs to provide a node to allow inter-process IO requests to be merged. A block device has one and only one request queue (schedule queue). All IO requests to the block device need to pass this common node. Therefore, the Queue Queue is another node that IO requests are merged. First review the core function of the generic block layer processing IO requests: blk_queue_bio(), the bio requests distributed by the upper layer will flow through the function, or store bio to the Plug List, or merge bio to the Elevator Queue, or generate requests for bio Insert directly into the Elevator Queue. The main processing flow of blk_queue_bio() is:
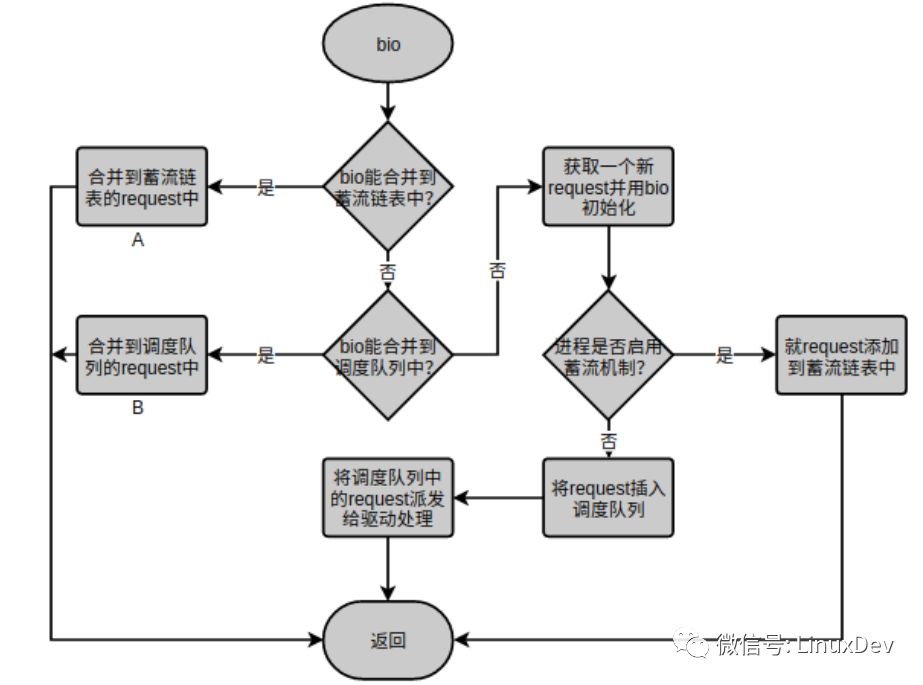
Among them, the "merge into the request of the storage chain list" identified by "A" is the "plug merge" described in the previous chapter. If bio cannot be merged into the flow chain list, it will try to merge into the "merge to the request of the dispatch queue" identified by "B". The "merge to the request of the dispatch queue" is only the first point of the "elevator merge". You may have discovered that blk_queue_bio() merges bio into the flow chain list or adds the request to the flow chain list. Then, from path 1, you can see that the request in the flow chain table is ultimately sent to the elevator scheduling queue. This is the second point of the "elevator merge". Please refer to the "Linux generic block layer introduction (part1: bio layer)" I previously wrote about the timing of the streamflow. Here are the two merge points:
Bio merged into elevator
Let's look at the code segment represented by B:
Blk_queue_bio:
Switch (elv_merge(q, &req, bio)) {
Case ELEVATOR_BACK_MERGE:
If (!bio_attempt_back_merge(q, req, bio))
Break;
Elv_bio_merged(q, req, bio);
Free = attempt_back_merge(q, req);
If (free)
__blk_put_request(q, free);
Else
Elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
Goto out_unlock;
Case ELEVATOR_FRONT_MERGE:
If (!bio_attempt_front_merge(q, req, bio))
Break;
Elv_bio_merged(q, req, bio);
Free = attempt_front_merge(q, req);
If (free)
__blk_put_request(q, free);
Else
Elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
Goto out_unlock;
Default:
Break;
}
The merge logic is basically similar to the "plug merge" method. The merge type is determined by calling the elv_merge interface first, and then the merge operation is called for bio_attempt_back_merge and bio_attempt_front_merge according to the backward merge or forward merge, respectively. Since the operation object is changed from the storage chain list to the elevator schedule Queue, there are a few more things to do after the bio merges:
1. Call elv_bio_merged. This function will call the elevator_bio_merged_fn interface registered by the elevator scheduler to notify the scheduler to do the corresponding processing. For the deadline scheduler, the interface is NULL.
2. Looking for advanced merges, refer to the description of advanced merges in the “Linux generic block layer introduction (part2:request layer)†I wrote earlier. If bio generates a backward merge, call attempt_back_merge to try backwards advanced. Merge, if bio produces a forward merge, then call atempt_front_merge to attempt a forward merge. The advanced merge interface of deadline is deadline_merged_requests. The merged request will be deleted from the dispatch queue. The following diagram shows the backward advanced merge process, the forward advanced merge empathy.
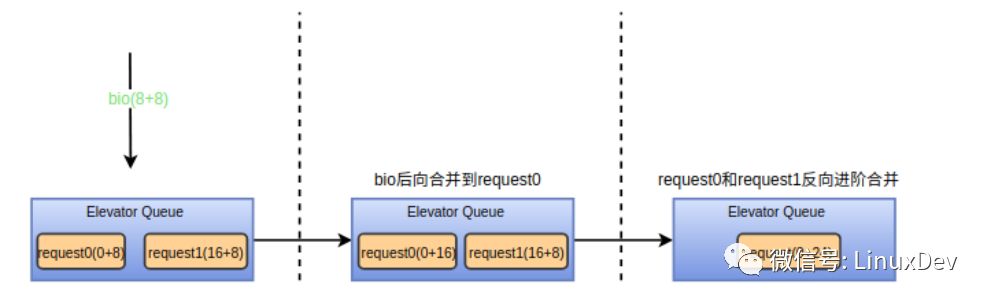
3. If an advanced merge is generated, the merged request can be released. Referring to the above figure, blk_put_request can be called for recycling. If only the bio merge is generated, the length of the merged request and the sector address will change. Elv_merged_request->elevator_merged_fn needs to be called to update the position of the merged request in the dispatch queue. The interface corresponding to deadline is deadline_merged_request. The corresponding operation is to remove the merged request from the dispatch queue first and then reinsert it.
The combined form of "bio merge to elevator" will only happen between processes, that is, only one process will not produce this kind of consolidation at the time of IO, because the process is dispatching IO requests to the dispatch queue or trying to associate bio with dispatch queue. When the request is merged, the queue holding the device is locked. Other processes cannot send requests to the dispatch queue. This is one of the main reasons why the common block layer single queue channel needs to develop multiple queues. Only the processes in the queue will be dispatched. When the request is dispatched to the driver layer one by one, the device queue lock will be reopened. That is, only when a process dispatches the request to the driver in the dispatch queue can the other processes have the opportunity to merge the bio to the request that has not been dispatched yet. in. Therefore, it is difficult to capture this form of merging through a simple IO test program. This has very high requirements on the IO generation timing of the two IO processes, so it is not demonstrated. Those who are interested can refer to the above github repository. There is a patch that delays the timing of the IO request by changing the kernel-specific request dispatch location. This allows the test program to artificially achieve this collision effect.
Request merged into elevator at streamflow
The generic block layer bleeder interface is: blk_flush_plug_list(). The main processing logic of the interface is shown in the figure below.
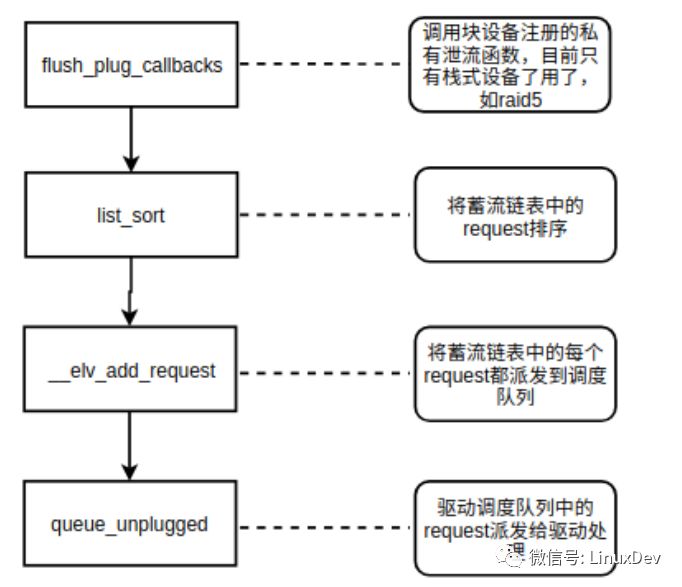
The point at which the request for merging occurs is __elv_add_request(). The blk_flush_plug_list will traverse each request in the flow-list and then add each request to the dispatch queue through the _elv_add_request interface. During the addition, it will try to merge with the existing request in the dispatch queue.
__elv_add_request:
Case ELEVATOR_INSERT_SORT_MERGE:
/*
* If we succeed in merging this request with one in the
* queue already, we are done - rq has now been freed,
* so no need to do anything further.
*/
If (elv_attempt_insert_merge(q, rq))
Break;
/* fall through */
Case ELEVATOR_INSERT_SORT:
BUG_ON(blk_rq_is_passthrough(rq));
Rq->rq_flags |= RQF_SORTED;
Q->nr_sorted++;
If (rq_mergeable(rq)) {
Elv_rqhash_add(q, rq);
If (!q->last_merge)
Q->last_merge = rq;
}
Q->elevator->type->ops.sq.elevator_add_req_fn(q, rq);
Break;
Leakage is taken when the ELEVATOR_INSERT_SORT_MERGE branch, as described in the comments let the flow of the request to call elv_attempt_insert_merge try to merge with the request in the scheduling queue, if not merged into the ELEVATOR_INSERT_SORT branch, the branch directly calls the elevator scheduler registration The elevator_add_req_fn interface inserts the new request into the proper position of the dispatch queue. The elv_rqhash_add is to do the hash index of the new request added to the dispatch queue. The advantage of doing so is to speed up the indexing speed of the merge request from the dispatch queue. When the flow is released, there are requests generated by other processes in the dispatch queue, and there are requests dispatched by the current process from the flow chain list (blk_flush_plug_list dispatches all requests to the dispatch queue and then queue_unplugged one time, instead of dispatching a request queue_unplugged. ). Therefore, "request to merge into elevator during streamflow" is both in-process and inter-process. The elv_attempt_insert_merge implementation only performs backward merges between requests, that is, only one request is merged into the tail of the request in the dispatch queue. This is enough for single-process IO, because blk_flush_plug_list has already made a list_sort (sector-sort) to the request in the list when the stream is released. I have previously submitted a patch (see github) that promotes the forward merge of inter-process requests, but it has not been received. The analysis of maintainer–Jens is such an IO scenario that it is difficult to happen. If such an IO scenario is generated, the application design is not. reasonable. It is not advisable to optimize an uncommon scenario by adding time and space. Finally, through an example to verify the process "request to merge into the elevator when the stream is released", the merger between the processes also has strong requirements on the timing of the request dispatch. We do not demonstrate here, there is a corresponding test patch and test method in github. . Iotc uses the following method to dispatch three write ios:
# ./iotc -d/dev/sdb -i
-i Specifies the IO mode to be INTERLEAVE_IO (alternate), which means that three write requests are initiated alternately by sectors: bio0(16 + 8), bio1(8 + 8), bio2(0 + 8). The observation of blktrace is:
Blktrace -d /dev/sdb -o - | blkparse -i -
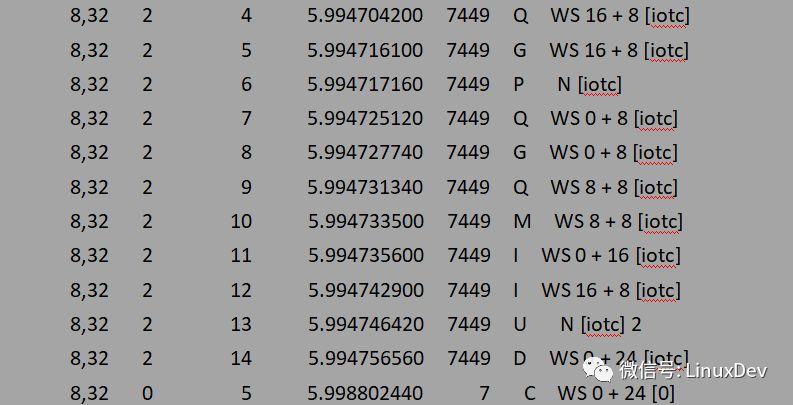
The above output can simply be resolved as:

Bio0 (16 + 8) reaches the plug list first, and bio1 (0 + 8) arrives and finds that it cannot merge with the request in the plug list, so a request is added to the plug list. When bio2(8+8) arrives, it first merges back with bio1. After the process triggers the streamflow, the streamflow interface function will sort the request in the plug list. Therefore, request(0+16) is dispatched to the dispatch queue first. At this time, the dispatch queue is empty and cannot be merged. Then dispatch the request(16+8), call the elv_attempt_insert_merge interface during dispatch to try to merge with other requests in the dispatch queue, and find that it can merge backward with request(0+16), so the two requests are merged into one and finally the device. Only one request (0+24) is dispatched by the driver. The entire process can be shown with the following diagram:
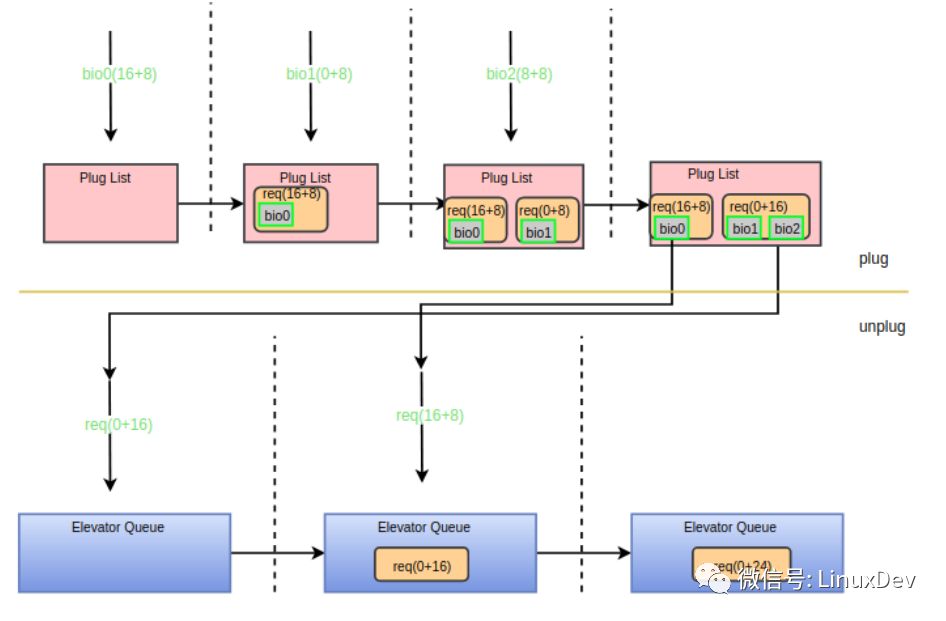
summary
Through the three layers of caching from the top of the cache, plug, and elevator, the IO generated by the application can be maximally merged, thereby increasing the IO bandwidth, reducing the IO latency, and extending the device lifetime. The page cache is the first to do both data buffering and IO merging, mainly for small IO merging, because the use of memory pages to do the cache, so the maximum IO unit after the merger is the page size, of course, for large IO, page cache will also Split it into page-by-page, which does not affect the final result, because there are plug and elevator complements. The plug list makes every effort to consolidate the IO generated within the process. From the perspective of the device, the IO generated within the process is more relevant and more likely to be merged. The plug list design is located above the elevator queue and is private to each process. Therefore, plug list is not only beneficial to IO merging, but also reduces the burden of elevator queue. Elevator queue is more responsible for the merger of inter-process IO, used to make up for the inadequacies of the plug list on the merger between processes, if it is with buffered IO, this IO merge basically does not appear. From the practical application perspective, IO merges occur more in the page cache and plug list.
DADNCELL 3V lithium-manganese buckle-type disposable battery adopts manganese dioxide with very stable chemical properties as positive materials and lithium with very high energy as negative electrode materials.
DADNCEL batteries have excellent safety performance, good sealing performance, stable discharge voltage and long storage life. At the same time, they have the characteristics of temperature and wide. The battery can work normally at -20°C ~ +60 °C. Therefore, it is often used in backup memory power supply of some products, such as computer motherboard and automotive alarm. Tire tester, handheld computer, industrial control motherboard, calculator, watch, shoe lamp, electronic thermometer, electronic toys, flashlight, tax control machine, medical device, small electronic gift, Bluetooth wireless products, multifunctional wireless remote control, PDA, MP3, electronic key, card radio, IC card, smart home Electrical, digital camera, mobile phone and other equipment.
All types of batteries developed by DADNCELL Lab do not involve any heavy metals in production, use and waste. They are green and environmentally friendly and can be disposed of with domestic waste.
3V Lithium Button Battery,Button Cells For Key Fob,High Specific Energy Coin Battery,Coin Cells For Computer Motherboard
Shandong Huachuang Times Optoelectronics Technology Co., Ltd. , https://www.dadncell.com