Editor's note: The author of this article is data scientist Jeremy Howard and natural language processing expert Sebastian Ruder. The goal is to help newcomers and laymen better understand their new paper. The paper shows how to classify texts automatically with less data and at the same time with higher accuracy than the original method. This article will use simple terms to explain how natural language processing, text categorization, migration learning, language modeling, and their methods combine these concepts. If you are already familiar with NLP and deep learning, you can go directly to the project home page.
Introduction
On May 14th, we published the paper Universal Language Model Fine-tuning for Text Classification (ULMFiT), which is a pre-training model and open source with Python. The paper has been peer-reviewed and will be reported on ACL 2018. The above link provides an in-depth explanation of the method of the dissertation, as well as the Python modules used, the training model, and the script to build your own model.

This model significantly improves the efficiency of text categorization. At the same time, code and training models allow each user to better solve the following problems with this new method:
Finding documents related to a legal case;
Identify spam, malicious comments, or robot reply;
Classifying positive and negative evaluations of goods;
Classify political dispositions of articles;
other
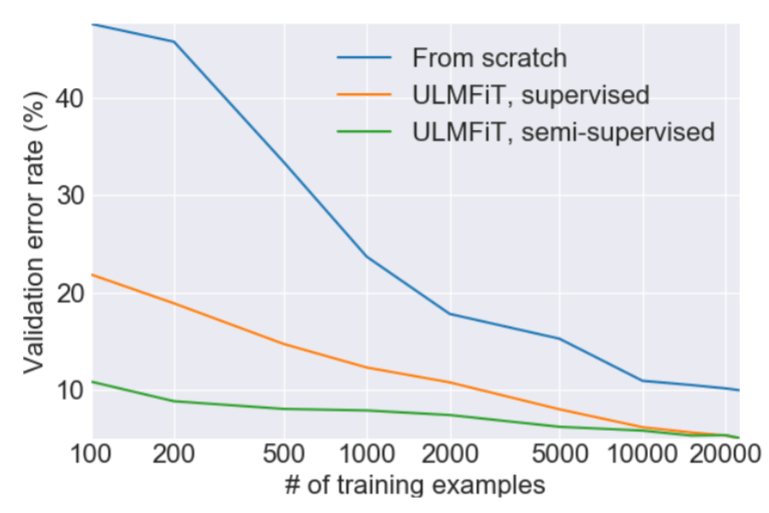
ULMFiT requires less than other methods
So what changes have the new technology brought about? Let's first look at what the summary section tells us, after which we will expand in the rest of the article to talk about what this means:
Migration learning has brought great changes to computer vision, but existing NLP technologies still need to improve models for specific tasks and start training from scratch. We propose an effective migration learning method that can be applied to any task in the NLP field. The technology proposed at the same time is crucial for adjusting the language model. Our method is superior to the existing technology in six text classification tasks. In addition, this method uses only 100 labeled samples to train, and the final performance is achieved from scratch. Tens of thousands of training data model performance.
NLP, deep learning and classification
Natural language processing is a special task in the field of computer science and artificial intelligence. As the name implies, it uses computers to process the world's languages. Natural language refers to the words we use everyday to communicate, such as English or Chinese, as opposed to professional languages ​​(computer code or musical notes). NLP has a wide range of applications, such as search, personal assistant, summary, and so on. In general, because the computer code written is difficult to express different emotions and nuances of the language, lack of flexibility leads to natural language processing is a very challenging task. Maybe you have already experienced dealing with NLP in your life, such as making a call with an automated reply robot or talking to Siri, but the experience is not very smooth.
In the past few years, we have begun to see that deep learning is surpassing traditional computers and has achieved good results in the NLP field. Unlike the previous set of fixed rules that need to be defined by the program, deep learning uses neural networks that learn rich nonlinear relationships directly from the data for processing calculations. Of course, the most significant achievement of deep learning is still in the field of computer vision (CV), and we can feel its rapid progress in the previous ImageNet image classification competition.
Deep learning has also achieved many successes in the field of NLP. For example, the automatic translation reported by The New York Times has had many applications. A common feature of these successful NLP missions is that they have a large amount of marked data available when training the model. However, until now, these applications can only be used on models that can collect a large number of tagged data sets, and also require that computer groups be able to calculate for a long time.
The most challenging problem of deep learning in the NLP field is the most successful problem in the CV field: classification. This refers to the classification of any item into a group, such as classifying a document or image into a dog or cat's data set, or determining whether it is positive or negative, and so on. Many problems in reality can be regarded as classification problems, which is why the success of deep learning classification on ImageNet has spawned various related commercial applications. In the field of NLP, the current technology can make "identification" well. For example, if you want to know whether a film critic is positive or negative, what you want to do is "sentiment analysis." But as the emotions of the article become more and more blurred, the model is difficult to judge because there is not enough learnable tag data.
Transfer learning
Our goal is to solve these two problems:
In the NLP problem, what should we do when we do not have large-scale data and computing resources?
Make the NLP easy to classify
The areas in which the participants of the research (Jeremy Howard and Sebastian Ruder) are engaged in can exactly solve this problem, namely transfer learning. Migration learning refers to the use of a model that solves a specific problem (such as classifying an ImageNet image) as a basis to solve similar problems. The common method is to fine-tune the original model. For example, Jeremy Howard once migrated the above classification model to CT image classification to detect whether there is cancer. Since the adjusted model does not need to learn from scratch, it can achieve higher accuracy than the model with less data and shorter calculation time.
For many years, simple migration learning using only a single weight layer was very popular, such as Google's word2vec embedding. However, in practice, a complete neural network contains many layers, so the use of migration learning on a single layer only solves the surface problems.
The point is, where do we need to migrate to learn to solve NLP issues? This problem plagued Jeremy Howard for a long time, but when his friend Stephen Merity announced the development of the AWD LSTM language model, this was a major advancement in language modeling. A language model is an NLP model that predicts what the next word in a sentence is. For example, the phone's built-in language model can guess which word you will play next when sending a message. This result is very important because a language model needs to have a good knowledge of grammar, semantics, and other natural language elements in order to correctly guess what you have to say next. We also have this ability when reading or classifying texts, but we do not know this.
We have found that applying this method to migration learning can help to become a common method for NLP migration learning:
This method is applicable regardless of file size, number, and tag type
It has only one structure and training process
It does not require customizing special engineering and preprocessing
It does not require additional related files or tags
start working
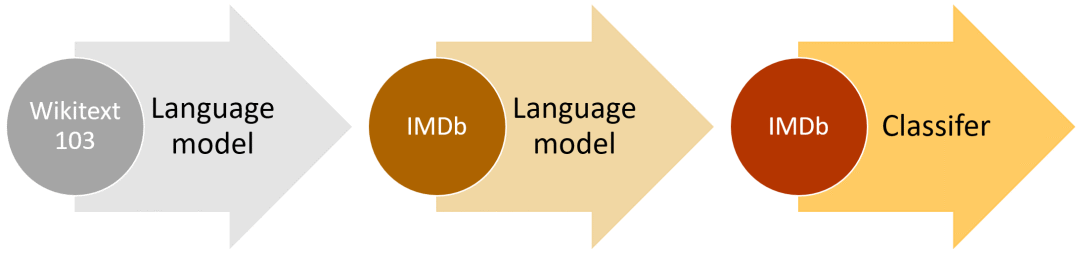
ULMFiT high-level method (taking IMDb as an example)
This method was tried before, but in order to achieve qualified performance, millions of texts are needed. We have found that by adjusting the language model, we can achieve better results. In particular, we found that if we carefully control the learning speed of the model and update the pre-training model to ensure that it does not forget what we learned earlier, then the model can be better adapted to the new data set. What is exciting is that we found that the model can learn better in a limited sample. On the two categories of text categorical datasets, we found that the effect of training our model on 100 samples is the same as the training effect from zero on 10,000 mark samples.
Another important feature is that we can use any large enough and common corpus to build a global language model that can be adjusted for any target corpus. We decided to use Stephen Merity's WikiText 103 dataset, which contains a subset of the English Wikipedia that has been processed and processed.
Many studies in the NLP field are in the English context. If you use non-English language training models, it will bring a series of problems. Usually, there are very few non-English language data sets exposed. If you want to train Thai text classification models, you have to collect data yourself. Collecting non-English text data means that you need to label yourself or look for annotators, because a crowdfunding service like Amazon's Mechanical Turk usually has only English callers.
With ULMFiT, we can easily train text-based classification models outside of English, which currently supports 301 languages. To make this task easier, we will publish a model zoo in the future, which includes pre-training models for various languages.
Future of ULMFiT
We have shown that this technique performs very well in different tasks under the same configuration. In addition to text classification, we hope that ULMFiT can solve other important NLP issues in the future, such as sequence tags or natural language generation.
The success of the ImageNet domain migration learning and pre-training ImageNet model has been transferred to the NLP field. Many entrepreneurs, scientists, and engineers currently use the adapted ImageNet model to solve important visual problems. Now that the tool is ready for language processing, we hope to see more applications in this area.
Although we have already demonstrated the latest developments in text classification, we need a lot of effort to make our NLP transfer learning work. There are many important papers in the field of computer vision analysis, and in-depth analysis of the results of migration learning in this field. Yosinski et al. tried to answer the question: "How can features in deep neural networks be migrated?" and Huh et al. studied "Why ImageNet is suitable for transfer learning." Yosinski even created a rich visual toolkit to help participants better understand the features of their computer vision models. If you solve a new problem with ULMFiT on a new data set, please share feedback in the forum!
Mini Air Fryer,Best Mini Air Fryer,Air Fryer Without Oil,Best No Oil Air Fryer
Ningbo ATAP Electric Appliance Co.,Ltd , https://www.atap-airfryer.com