For the computing industry, no concept should be more popular than artificial intelligence (AI) in the past 2016. In 2017, experts said that the demand for the artificial intelligence ecosystem will grow more rapidly. The main focus is on the "inference engine" that is more suitable for deep neural networks to find performance and efficiency.
Today's deep learning systems rely on software-defined networks and the enormous computing power generated by massive data learning, and rely on this to achieve the goal; unfortunately, this type of computing configuration is difficult to embed into those computing power, memory capacity and In systems with limited bandwidth (such as cars, drones, and IoT devices).
This brings a new challenge to the industry – how to embed deep neural network computing capabilities into end devices through innovation. Remi El-Ouazzane, chief executive of Movidius, a computer vision processor designer (which has been acquired by Intel), said a few months ago that deploying artificial intelligence at the edge of the network would be a big trend.
When asked why artificial intelligence was “rushed†to the edge of the network, Marc Duranton, an academician of the French Atomic Energy Commission (CEA) architecture, IC design and Embedded Software (Architecture, IC Design and Embedded Software), proposed three reasons: Safety, privacy, and economy; he believes that these three points are important factors driving the industry to process data at the terminal, and the future will generate more "information to convert data into information as soon as possible".
Duranton pointed out that if you want to drive autonomous vehicles, if the goal is safety, those autopilot functions should not rely solely on uninterrupted network connections; for example, old people fall at home, this situation should be on the spot by local monitoring devices. Judging it, considering the privacy factor, this is very important. He added that it is not necessary to collect all the images of 10 cameras in the home and transmit them to trigger an alarm, which also reduces power consumption, cost and data capacity.
AI competition officially launched
In all respects, chip vendors are already aware of the growth needs of the inference engine; many semiconductor companies, including Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) and Nvidia (Drive PX), are racing to develop low-power A high-performance hardware accelerator that allows machine learning to be performed better in embedded systems.
From the perspective of the actions of these vendors and the development direction of SoC, in the post-smart phone era, the inference engine has gradually become the next target market pursued by semiconductor manufacturers.
Earlier this year, Google introduced the tensor processing unit (TPU), which is a turning point in the industry to actively promote machine learning chip innovation; Google said in the release of the chip, TPU performance per watt compared to the traditional FPGA and GPU It will be a higher level, and it is pointed out that this accelerator has also been applied to the AlphaGo system, which has been popular all over the world at the beginning of this year. But so far Google has not disclosed the specification details of the TPU, nor does it intend to sell the component in the commercial market.
Many SoC practitioners have come to the conclusion from Google's TPU that machine learning requires a customized architecture; but when they design chips for machine learning, they are confused about the architecture of the chip and want to know Is there a tool in the industry to evaluate the performance of deep neural networks (DNN) in different modalities?
Performance assessment tool will be available soon
CEA said the organization is ready to explore different hardware architectures for the inference engine. They have developed a software architecture called N2D2 that helps design engineers explore and generate DNN architectures; Duranton points out: "The purpose of our tool development Is to choose the right hardware target for DNN." CEA will release N2D2 open source in the first quarter of 2017.
N2D2 is characterized by not only comparing hardware based on recognition accuracy, but also performing comparisons in terms of processing time, hardware cost, and power consumption; Duranton said, because of the deep learning for different applications, the hardware configuration required The parameters will vary, so the above comparisons are very important. N2D2 provides a performance reference standard for existing CPUs, GPUs, and FPGAs, including multicore and numerous cores.
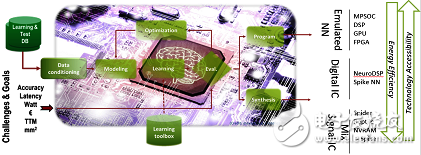
N2D2 operating principle
Barrier to edge computing
CEA has conducted in-depth research on how to extend DNN to edge computing (edge ​​compuTIng); Duranton pointed out that the biggest obstacle is that the "floating point" server solution is not applicable because of power consumption, memory size and latency. Other obstacles include: "Requires a lot of MAC, bandwidth and on-chip memory capacity."
So, using integers (Integers) instead of floating-point operations is the most important issue... Is there anything else? Duranton believes that this proprietary architecture also requires new coding methods, such as "spike coding"; CEA researchers have studied the characteristics of neural networks and found that such networks can tolerate operational errors, making them suitable for use in "Approximate computaTIon".
In this way, even binary coding is not required; and Duranton explains that the benefits are temporal coding such as spike coding, which provides more energy efficient results in edge operations. Spike coding is attractive because of spike coding—or event-based—the system can show how data in the actual nervous system is decoded.
In addition, event-based coding is compatible with dedicated sensors and pre-processing. This extremely similar encoding to the nervous system makes analog and digital mixed signals easier to implement and helps researchers create low-power, small hardware accelerators.
There are other factors that can accelerate the progression of DNN to edge operations; for example, CEA is considering the potential for adjusting the neural network architecture itself to edge computing. Duranton pointed out that people have begun to discuss neural networks using the "SqueezeNet" architecture instead of the "AlexNet" architecture. It is understood that the former requires one-fifth of the parameters required for the same accuracy as the latter; such simple configuration It is critical for edge operations, topology, and reducing the number of MACs.
Duranton believes that the ultimate goal is to convert classic DNN into an "embedded" network.
CEA's ambition is to develop neuromorphic circuits; the research organization believes that such chips are an effective complement to information from the proximity sensor's data (informaTIon) in deep learning applications.
Before achieving the above goals, CEA considered several expediencies; development tools such as D2N2 are important for chip designers to develop high-quality custom DNN solutions with per tera TOPS (tera operaTIons per second per Watt) performance. .
For those who want to use DNN in edge computing, there is also real hardware that can be tested—the ultra-low-power programmable accelerator P-Neuro from CEA; the current P-Neuro neural network processing unit is FPGA Based on this, Duranton said that CEA is about to turn the FPGA into an ASIC.
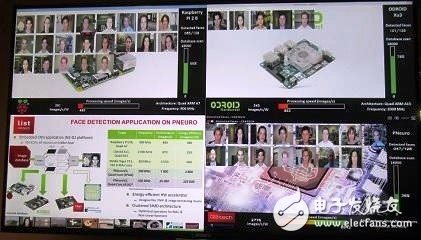
Duranton used the FPGA-based P-Neuro in the CEA lab to showcase the Convolutional Neural Network (CNN) for the face and P-Neuro with the embedded CPU (on the Raspberry Pi). The four-core ARM processor and the Android platform using the Samsung Exynos processor are all performing the same embedded CNN application, and the task is to perform "face feature extraction" in a database containing 18,000 images.
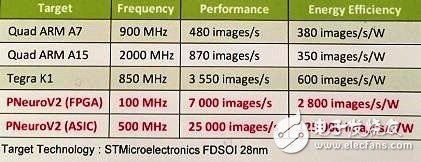
Performance comparison between P-Neuro and embedded CPU/GPU performing the same face recognition task
As shown in the above table, the speed of P-Neuro is 6,942 images per second, and the energy efficiency is 2,776 images per watt; compared with the embedded GPU (Tegra K1), P-Neuro operating at 1000MHz Faster and more energy efficient. P-Neuro is built on a clustered SIMD architecture that supports optimized memory tiering and internal linking.
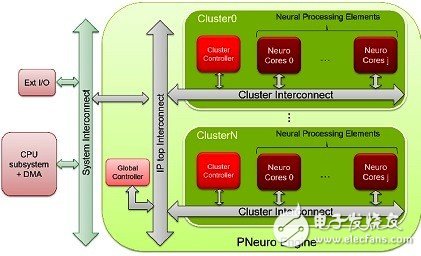
P-Neuro function block
But for CEA researchers, P-Neuro is only a short-term solution; the current P-Neuro is built with full CMOS components and binary coded; the team is also building full CMOS components using spike coding. To take advantage of advanced process advantages and breakthroughs in density and power, the team set a higher goal.
Carlo Reita, director of marketing and strategy for nanoelectronics at CEA-Leti, said in an interview that it is important to use advanced chip and memory technology for the physical design of dedicated components; one of them is the conventional monolithic of CoolCube using CEA-Leti 3D integration technology, another solution is to use resistive memory (Resistive RAM) as a synaptic component. In addition, advanced technologies such as FD-SOI and nanowires will also play a role.
Neuromorphic processor
At the same time, the EU under the "EU Horizon 2020" program, trying to build a neuromorphic architecture chip, can support the most advanced machine learning, and the spine-based learning mechanism; the research project is called NeuRAM3, the goal is to be ultra-low Power-consuming, scalable, and highly configurable neural architecture that creates components that consume 50 times less power than traditional digital solutions in specific applications.
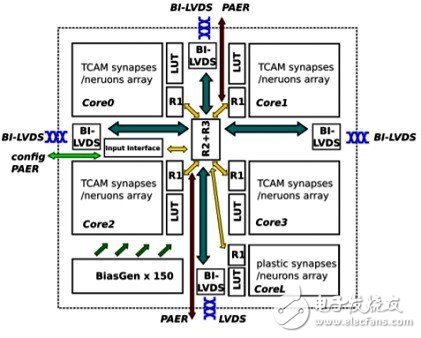
Neuromorphic processor architecture
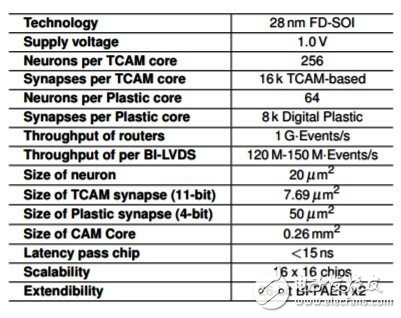
Neuromorphic processor basic specifications
Reita said that CEA is also involved in the NeuRAM3 project, whose research goals are closely related to the mission of the project, including the development of monolithically integrated 3D technology using FD-SOI processes, and the integration of resistive memory synaptic components. Application; she also pointed out that the new generation of mixed-signal multi-core neuromorphic components developed by the NeuRAM3 project can significantly reduce power consumption compared to IBM's TrueNorth brain-inspired operands.
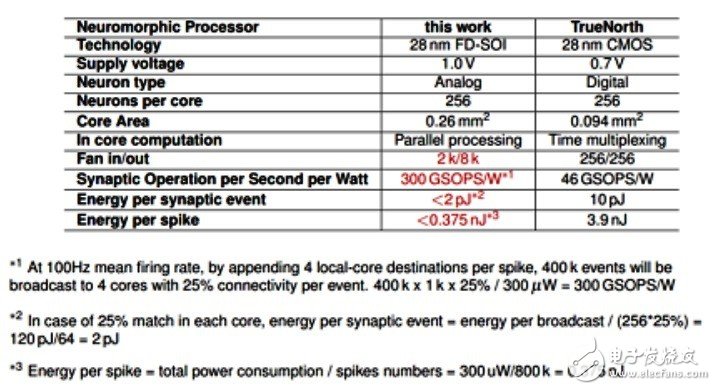
Comparison of NeuRAM3 neuromorphic components with IBM TrueNorth
Participants in the NeuRAM3 project include IMEC, IBM Zurich Research Center, ST Microelectronics, CNR (The National Research Council in Italy), Spanish research institute IMSE (El Instituto de Microelectronica de Sevilla in Spain), Switzerland The University of Zurich and Jacobs University in Germany.
Smart Breathing Range Hood,Breathing Range Hood,Low Noise Range Hood,Black Stainless Range Hood
JOYOUNG COMPANY LIMITED , https://www.globaljoyoung.com