Recently, Oculus added two features called "ParTIes" and "Rooms" for the Samsung Gear VR Virtual Reality Helmet, designed to increase the user's interaction when using VR devices. In 2016, FaceBook founder Zuckerberg also said at the VR program, "VR will become the next computing platform that will lead people to completely subvert the existing social network model." VR social concept is being fired, but VR The road is not so beautiful. First of all, the problem facing today is the problem of voice interaction. Today, Xiaobian is here to talk about the issue of VR voice interaction.
First, the University of Science and Technology Flight Voice Engine System
InterReco speech recognition system
HKUST launches the world's leading InterReco speech recognition system. InterReco drives self-service voice services and voice search services. It is the core engine of voice business (V-Commerce). At present, InterReco speech recognition systems have been able to take advantage of advanced self-service voice service solutions to address the growing demand for information consulting, electronic transactions and customer service. InterReco-based solutions help users easily and easily access information and services from anywhere, anytime, anywhere, with an efficient, stable and convenient application experience.
The InterReco speech recognition system adopts a distributed architecture and inherits the high stability characteristics of Keda Xunfei's proven carrier-grade voice platform, which can meet the high reliability and high availability requirements of carrier-class applications. In view of the difficulty in integrated development of traditional speech recognition products and the cumbersome business design, InterReco products greatly simplify the complexity of integrated development and business development, and provide a convenient and efficient development environment for system integrators and business developers.
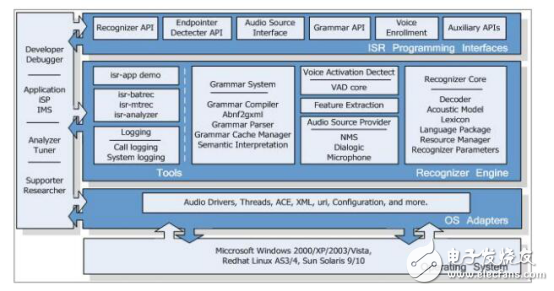
The main functional components and structure of InterReco products
The InterReco speech recognition system mainly includes three levels: application interface, recognition engine and operating system adaptation. These three logical layers together form a complete InterReco system architecture.
The application interface is the development interface provided by the InterReco system, and the integration developer should pay attention to the definition, function and usage of these interfaces. The recognition engine provides the core speech recognition function and acts as a function implementer of the application interface;
For ease of development and use, the system provides a range of efficient, easy-to-use tools at this level. The operating system adaptation layer shields the complexity of multiple operating systems and provides operating system-related underlying support for the recognition engine.
InterReco speech recognition system can be divided into four subsystems: Grammar, Recognizer Core, Voice AcTIva Detector and Audio Source. The main design and development of the system will be Follow these subsystems.
Embedded Voice Aisound Series
Similarly, HKUST also provides carrier-grade and embedded speech synthesis technology. The embedded voice Aisound series is a global leading speech synthesis technology with small size, low resource consumption and high efficiency. It is mainly used in the embedded field. Speech synthesis software module. Suitable for voice broadcast and application needs in different industries.
Keda Xunfei embedded voice solution mainly provides: XFS3031CNP Chinese speech synthesis chip, XFS4243CE Chinese and English speech synthesis module, XFS5152CE Chinese and English speech synthesis chip, XF-S4240 Chinese speech synthesis module and other four speech synthesis programs, has been successfully applied to the car Dispatcher, information machine, weather warning machine, attendance machine, queue machine, hand-held smart meter, tax control machine and other information terminal products. In addition, the voice engine also provides lightweight voice synthesis software Aisound, which supports a wide range of embedded platforms and support functions.
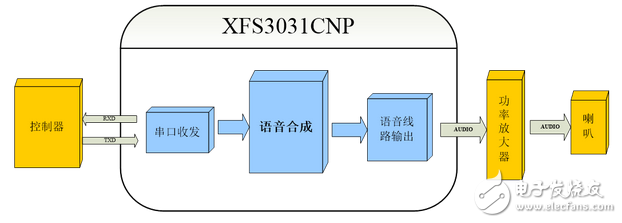
XFS3031CNP Chinese voice chip system composition diagram
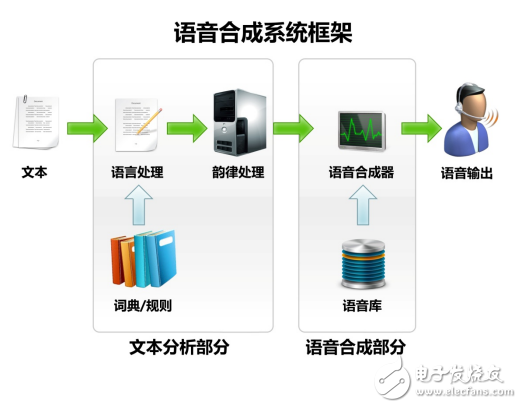
Keda Xunfei speech synthesis system framework
Second, Yunzhisheng "far field speech recognition technology" program
In terms of voice cloud platform, Yunzhisheng has its own technical advantages in three aspects: speech recognition, semantic understanding and speech synthesis. Voice interaction is an interactive portal in the VR field. Yunzhisheng emphasizes the interaction technology that adapts to various daily scenes. At present, Yunzhisheng mainly targets four vertical fields: voice cloud platform, smart car, smart home, education and so on. Speech recognition technology provides a solution.
The latest voice technology developed by Yunzhisheng - "far field speech recognition scheme based on dual microphone array". This solution uses the world's leading SSP technology to effectively suppress the noise and reverberation effects outside the user's voice, so that far-field pickup can be effectively performed in more than 95% of the scenes, with the far-field voice of Yunzhisheng The recognition engine ensures a precise recognition within a distance of 5 meters. At the same time, since the solution only requires 2 microphones, the installation position is flexible and there is no need to consider the orientation of the device.
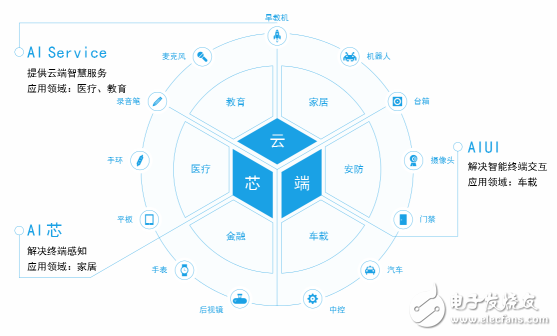
Yunzhisheng "cloud core" ecology
Yunzhisheng provides voice recognition, semantic understanding, speech synthesis, voiceprint recognition and other voice core technologies. Yunzhisheng Open Platform supports one-stop voice application development, can create voice applications independently, and can add corresponding matching requirements. The development of the SDK integration package is completed through the platform type setting, and the voice product is released online.
Third, the sound network Agora.io real-time voice system
The sound network Agora.io voice SDK uses the world's unique 32khz ultra-wideband sound quality, which is four times the sound quality of ordinary telephones, and provides a multi-channel sound system to achieve the "listening voice" in the VR experience, comparable to 3D sound. More importantly, real-time voice can also be perfectly integrated with the game background music, which greatly increases the user's presence.
In addition to audio processing optimization, the sound network Agora.io relies on a globally deployed virtual communication network to ensure that gaming applications are provided with no-card, no-drop, ultra-low latency experience, especially for unique optimizations in poor network conditions. It can greatly improve the interaction between game applications and live games. This "heavyweight weapon" is easy for developers to complete with just 30 minutes of integration.
In response to the inability to achieve basic listening, Ageo.io has introduced a multi-channel sound system solution. Through the integrated voice call SDK, the voice codec NOVA with real-time high-definition sound quality and 32khz super-band frequency can be obtained, which realizes the stereoscopic surround of the sound in the VR picture, allowing the user to feel the sound from all directions and eliminate the intelligent echo. And the noise reduction function allows the user to accurately position the space through the sound to achieve a good picture immersion experience.
Packages For Wireless Communications,High Power Red Lasers,High Power Diode Lasers,High Power Pulsed Lasers
Shaanxi Xinlong Metal Electro-mechanical Co., Ltd. , https://www.cnxlalloyproduct.com