Is the GeForce RTX 20 series graphics card that NVIDIA shockingly released this week worth buying? How to choose the right GPU for you? This article analyzes the problem in depth and provides suggestions to help you make the most suitable choice.
Deep learning is often ridiculed as "alchemy", then GPU is an indispensable "alchemy furnace" for deep learning researchers.
Deep learning is a field with high computational requirements. Which GPU to choose and how many GPUs to choose will fundamentally determine your deep learning experience. If there is no GPU, it may take months to wait for the experiment to complete, or the experiment will run all day and just see the results of failure.
With a good and reliable GPU, alchemists can quickly iterate the design and parameters of the deep network, and run experiments in days instead of months, hours instead of days, and minutes instead of hours. Therefore, it is important to make the right choice when buying a GPU.

Tim Dettmers' GPU selection
So how to choose the GPU that suits you? The author of this article, Tim Dettmers, has a master's degree in informatics from the University of Lugano, Switzerland, and is keen to develop his own GPU clusters and algorithms to accelerate deep learning. This article delves into this issue and provides suggestions to help you make the most suitable choice.
Is the GeForceRTX 20 series graphics card that NVIDIA shockingly released this week worth buying? What is its capacity and cost performance? This article also gives an analysis.
Let's start with the conclusion: RTX 2080 is the most cost-effective choice. Of course, the GTX 1080/1070 (+Ti) card is still a very good choice.

The GPU recommendations given by the author are as follows:
Overall, the best GPU is: RTX 2080 Ti
Cost-effective, but expensive: RTX 2080, GTX 1080
Cost-effective and affordable: GTX 1070, GTX 1070 Ti, GTX 1060
The data set I use> 250GB: RTX 2080 Ti or RTX 2080
I don't have much budget: GTX 1060 (6GB)
I am poor: GTX 1050 Ti (4GB) or CPU (prototyping) + AWS/TPU (training)
I participate in the Kaggle competition: GTX 1060 (6GB) for prototyping, AWS for final training; use fastai library
I am a computer vision researcher: RTX 2080 Ti; I can upgrade to RTX Titan in 2019
I am a researcher: RTX 2080 Ti or GTX 10XX -> RTX Titan (look at the storage requirements of your current model)
I want to build a GPU cluster: this is very complicated, you can refer to this article[1]
I have just started deep learning, and I am serious: you can start with GTX 1060 (6GB), or the cheap GTX 1070 or GTX 1070 Ti. It depends on what you want to do next (go to a startup, participate in Kaggle competitions, do research, apply deep learning), then sell the original GPU and buy a more suitable one
Comprehensive comparison: NVIDIA, AMD, Intel, Google, Amazon
NVIDIA: the absolute king
NVIDIA's standard library makes it very easy to build the first deep learning library in CUDA, while AMD's OpenCL does not have such a powerful standard library. This leading advantage, coupled with NVIDIA's strong community support, quickly expanded the size of the CUDA community. This means that if you use NVIDIA GPU, you can easily find support when you encounter problems; if you write your own CUDA program, it is also easy to find support and advice, and you will find that most deep learning libraries are provided for NVIDIA GPU Best support. For NVIDIA GPU, this is a very powerful advantage.
On the other hand, Nvidia now has a policy to use CUDA in the data center to only allow Tesla GPUs, not GTX or RTX cards. The meaning of "data center" is vague, but it means that because of concerns about legal issues, research institutions and universities are often forced to buy expensive and inefficient Tesla GPUs. However, Tesla card does not have a big advantage over GTX and RTX cards, and the price is 10 times higher.
Nvidia can implement these policies without any major obstacles, which shows its monopoly power-they can do whatever they want, and we must accept these terms. If you choose the main advantages of NVIDIA GPU in terms of community and support, you also need to accept their arbitrary mercy.
AMD: powerful, but lack of support
HIP unifies NVIDIA and AMD GPUs under a common programming language through ROCm, and is compiled into their respective GPU languages ​​before being compiled into GPU assembly code. If all our GPU code is in HIP, this will be an important milestone, but it is quite difficult because the TensorFlow and PyTorch code bases are difficult to port. TensorFlow has some support for AMD GPU, all major networks can run on AMD GPU, but if you want to develop a new network, you may miss some details, which may prevent you from achieving the desired results. The ROCm community is not very large, so it is not easy to solve problems quickly. In addition, AMD does not seem to have much funds for deep learning development and support, which slows down the momentum of development.
However, AMD GPU performance is not worse than NVIDIA GPU performance, and the next generation AMD GPU Vega 20 will be a very powerful processor with a computing unit similar to Tensor Core.
In general, for ordinary users who only want the GPU to run smoothly, I still cannot clearly recommend AMD GPU. More experienced users should have few problems, and supporting AMD GPU and ROCm/HIP developers will help combat Nvidia’s monopoly, which will benefit everyone in the long run. If you are a GPU developer and want to make important contributions to GPU computing, then AMD GPUs may be the best way to make a good long-term impact. For others, NVIDIA GPUs are a safer choice.
Intel: Still need to work
My personal experience with Intel Xeon Phis is very disappointing, and I don’t think they are real competitors of NVIDIA or AMD graphics cards: if you decide to use Xeon Phi, please note that the support you can get when you encounter problems is very limited. The segment is slower than the CPU, and it is very difficult to write optimized code. It does not fully support the features of C++++ 11, does not support some important GPU design pattern compilers, and has poor compatibility with other libraries (such as NumPy and SciPy) since the BLAS routine. There are many setbacks that I haven't encountered.
I am looking forward to the Intel Nervana Neural Network Processor (NNP) because its specifications are very powerful, it can allow new algorithms, and may redefine the way neural networks are used. The NNP is scheduled to be released in the third quarter / fourth quarter of 2019.
Google: On-demand processing is cheaper?
Google TPU has developed into a very mature cloud-based product with extremely high cost-effectiveness. The easiest way to understand TPU is to think of it as multiple GPUs packaged together. If we look at the performance indicators of V100 and TPUv2 that support Tensor Core, we will find that for ResNet50, the performance of these two systems is almost the same. However, Google TPU is more cost-effective.
So, is TPU a cloud-based cost-effective solution? It can be said that it is, or it can be said that it is not. Whether in papers or in daily use, TPU is more cost-effective. However, if you use the best practices and guidelines of the fastai team and the fastai library, you can achieve faster convergence at a lower price-at least for object recognition using volumes and networks.
Using the same software, TPU can be even more cost-effective, but there are also problems: (1) TPU cannot be used in the fastai library, namely PyTorch; (2) TPU algorithm mainly depends on Google’s internal team, (3) there is no unified High-level libraries can implement good standards for TensorFlow.
These three points hit TPU because it requires separate software to keep up with the new deep learning algorithms. I believe that the Google team has completed these tasks, but it is not clear how good the support for certain models is. For example, TPU's official GitHub repository has only one NLP model, and the rest are computer vision models. All models use convolution, and none of them are recurrent neural networks. However, over time, software support is likely to improve rapidly and costs will drop further, making TPU an attractive option. However, currently TPU seems to be most suitable for computer vision, and as a supplement to other computing resources, rather than the main deep learning resources.
Amazon: reliable but expensive
Since the last update of this blog post, AWS has added many new GPUs. However, the price is still a bit high. If you suddenly need additional calculations, for example, all GPUs are in use before the deadline of the research paper, AWS GPU instances may be a very useful solution
However, if it is cost-effective, then you should ensure that you only run a few networks and know exactly that the parameters selected for the training run are close to optimal. Otherwise, the cost-effectiveness will be greatly reduced, and it is not as useful as a dedicated GPU. Even if the fast AWS GPU is temptingly solid, the gtx1070 and up will be able to provide good computing performance for a year or two without much cost.
In summary, AWS GPU instances are very useful, but they need to be used wisely and carefully to ensure cost-effectiveness. Regarding cloud computing, we will discuss it later.
What makes one GPU faster than the other?
When choosing a GPU, your first question may be: For deep learning, what is the most important feature that makes GPU computing fast? Is it the CUDA Core, the clock speed, or the size of the RAM?
Although a good simplification suggestion should be "pay attention to memory bandwidth", I no longer recommend this. This is because GPU hardware and software have been developed over the years so that GPU bandwidth is no longer the best indicator of its performance. The introduction of Tensor Core into consumer GPUs further complicates this problem. Now, the combination of bandwidth, FLOPS and Tensor Core is the best indicator of GPU performance.
In order to deepen your understanding and make wise choices, it is best to understand which parts of the hardware enable the GPU to quickly perform the two most important tensor operations: matrix multiplication and convolution.
A simple and effective way to consider matrix multiplication is that it is bandwidth-constrained. If you want to use LSTM and other recurrent networks that require a lot of matrix multiplication, memory bandwidth is the most important feature of GPU.
Similarly, convolution is subject to computational speed constraints. Therefore, for ResNets and other convolutional architectures, the GPU's TFLOP is the best indicator of its performance.
Tensor Cores slightly changed this balance. Tensor Cores are dedicated computing units that can speed up calculations-but will not increase memory bandwidth-so for convolutional networks, the biggest advantage is that Tensor Cores can speed up 30% to 100%.
Although Tensor Cores can only speed up calculations, they also allow the use of 16-bit numbers for calculations. This is also a big advantage of matrix multiplication, because the size of the number is only 16-bit instead of 32-bit. In a matrix with the same memory bandwidth, the number of numbers can be transmitted twice. Generally speaking, LSTM using Tensor Cores can be accelerated by 20% to 60%.
Please note that this acceleration does not come from Tensor Cores itself, but from its ability to perform 16-bit calculations. The 16-bit algorithm on AMD GPUs is as fast as the matrix multiplication algorithm on NVIDIA cards with Tensor Cores.
A big problem with Tensor Cores is that they require 16-bit floating point input data, which may cause some software support issues, because the network usually uses 32-bit values. If there is no 16-bit input, Tensor Cores are useless.
However, I think these problems will be solved soon, because Tensor Cores are too powerful, and now consumer GPUs also use Tensor Cores, so more and more people will use them. With the introduction of 16-bit deep learning, we actually doubled the memory of the GPU because the parameters contained in the GPU with the same memory have doubled.
In general, the best rule of thumb is: if you use RNN, look at bandwidth; if you use convolution, look at FLOPS; if you can afford it, consider Tensor Cores (don’t buy Tesla cards unless you have to )
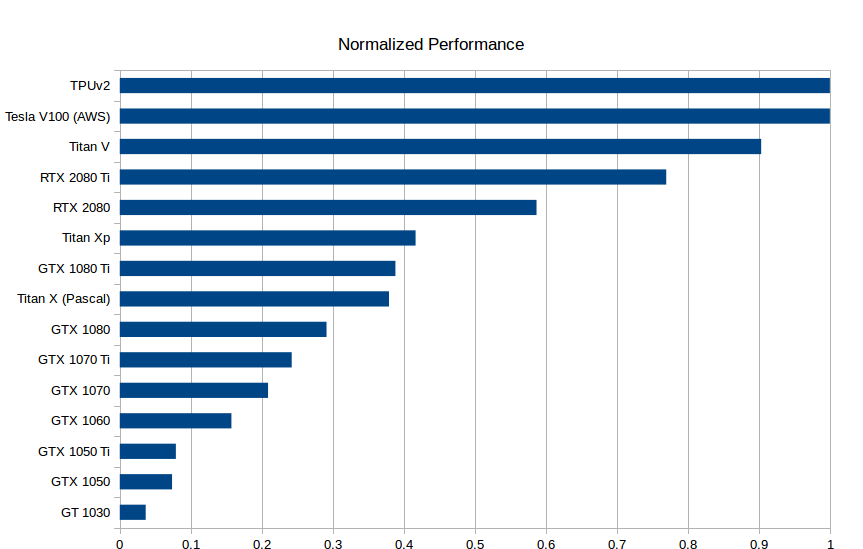
Standardized raw performance data for GPU and TPU. The higher the better. The speed of the RTX 2080 Ti is approximately twice that of the GTX1080 Ti: 0.75 vs 0.4.
Cost analysis
Cost performance is perhaps the most important category of indicators to consider when choosing a GPU. I did a new cost performance analysis on this, which considered the memory bit width, computing speed and Tensor core. In terms of price, I refer to the prices on Amazon and eBay, and the reference weight ratio is 1:1. Then I examined the performance indicators such as LSTM and CNN with and without Tensor Core. The average performance score is obtained from these index numbers through the standardized geometric average, and the cost-effective numbers are calculated. The results are as follows:
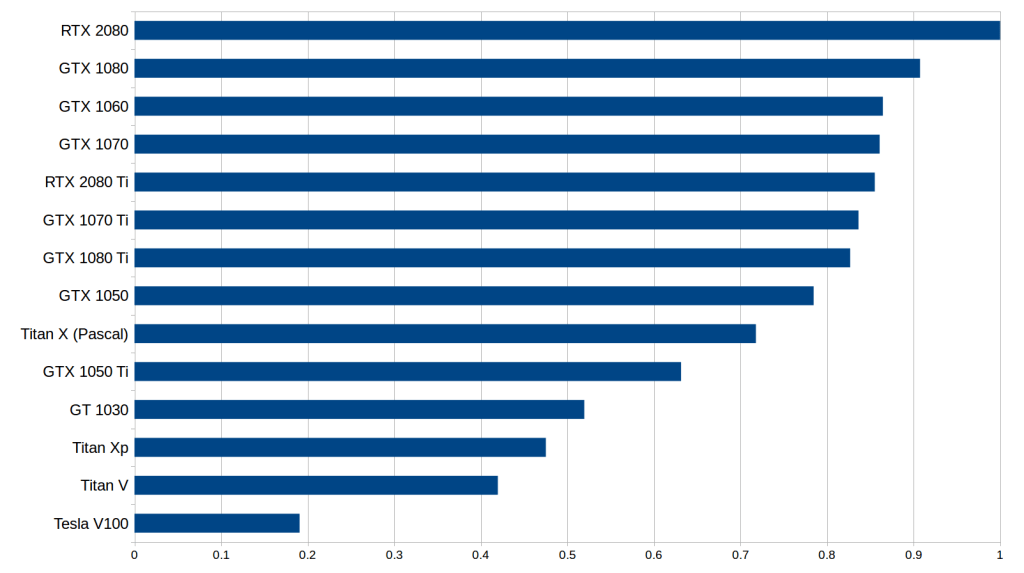
The cost-effective results after standardized processing take into account factors such as memory bandwidth (RNN), calculation speed (convolutional network), and whether to use Tensor Cores. The higher the number, the better. The price/performance ratio of RTX2080 is about 5 times that of Tesla V100.
Please note that the numbers for RTX 2080 and RTX 2080 Ti may be a little bit watery, because the actual hard performance data has not been released yet. I estimate the performance based on the roofline model of matrix multiplication and convolution under this hardware and the Tensor Core benchmark numbers from V100 and Titan V. As there is currently no hardware specification number, RTX 2070 is not included at all. Note that RTX 2070 may easily beat the other two RTX series graphics cards in terms of cost-effectiveness, but there is currently no data support.
From preliminary data, we found that RTX 2080 is more cost-effective than RTX 2080 Ti. Compared with RTX2080, RTX 2080 Ti's Tensor core and bandwidth have increased by about 40%, and the price has increased by 50%, but the performance has not increased by 40%. For LSTM and other RNNs, the performance increase from the GTX 10 series to the RTX 20 series is mainly due to the support for 16-bit floating point calculations, not the Tensor core itself. Although the performance of the convolutional network should theoretically increase linearly with the Tensor core, we did not see this from the performance data.
This shows that other parts of the convolutional architecture cannot achieve performance improvements with the Tensor core, and these parts also account for a large proportion of the overall computing requirements. Therefore, RTX 2080 is more cost-effective, because it has all the functions needed to obtain performance improvements (GDDR6 + Tensor core) than the GTX 10 series, and it is also cheaper than the RTX 2080 Ti.
In addition, readers are reminded that there are some problems in this analysis, and the interpretation of these data needs to be cautious:
(1) If you buy a graphics card that is cost-effective but has a slower computing speed, the computer may no longer have more GPU space at some point, which will result in a waste of resources. Therefore, this chart is biased towards expensive GPUs. In order to offset this deviation, the original performance chart should also be evaluated.
(2) This cost performance chart assumes that readers will use 16-bit calculations and Tensor cores as much as possible. In other words, for 32-bit computing, RTX-based graphics cards are very cost-effective.
(3) There have been rumors that a large number of RTX 20 series graphics cards have been delayed due to the decline in the cryptocurrency market. Therefore, popular mining GPUs like GTX 1080 and GTX 1070 may quickly drop in price, and their price/performance ratio may increase rapidly, making the RTX 20 series less advantageous in terms of price/performance. On the other hand, the price of a large number of RTX 20 series graphics cards will remain stable to ensure that they are competitive. It is difficult to predict the future prospects of these graphics cards.
(4) As mentioned above, there is currently no hard and unbiased performance data on RTX graphics cards, so all these numbers cannot be taken too seriously.
It can be seen that it is not easy to make the right choice among so many graphics cards. However, if readers take a balanced view of all these issues, they can actually make their own best choices.
Deep learning in the cloud
GPU instances on AWS and TPU in Google Cloud are both viable options for deep learning. Although TPU is slightly cheaper, it lacks the versatility and flexibility of AWS GPUs. TPU may be the first choice for training target recognition models. But for other types of workloads, AWS GPU may be a safer choice. The advantage of deploying cloud instances is that you can switch between GPU and TPU at any time, and even use them at the same time.
However, please pay attention to the opportunity cost problem in this scenario: if readers learn the skills to successfully complete the workflow using AWS instances, they will lose the time to work with personal GPUs, and they will not be able to acquire the skills to use TPU. If you use a personal GPU, you cannot expand to more GPUs/TPUs through the cloud. If you use TPU, you cannot use TensorFlow, and it is not easy to switch to the AWS platform. The learning cost of a smooth cloud workflow is very high. If you choose TPU or AWS GPU, you should carefully weigh this cost.
Another question is about when to use cloud services. If readers want to learn deep learning or need to design prototypes, then using a personal GPU may be the best choice, because cloud instances may be expensive. However, once you have found a good deep network configuration and only want to use the data parallelism with the cloud instance to train the model, using cloud services is a reliable way. In other words, a small GPU is enough for prototyping, and you can also rely on the powerful functions of cloud computing to expand the scale of experiments and achieve more complex calculations.
If you don’t have enough funds, using cloud computing instances may also be a good solution, but the problem is that when you only need a little prototyping, you can only buy a lot of computing power in time, causing costs and computing power. waste. In this case, people may want to prototype on the CPU and then perform fast training on the GPU/TPU instance. This is not an optimal workflow, because prototyping on the CPU can be very painful, but it is indeed a cost-effective solution.
in conclusion
In this article, readers should be able to understand which GPU is right for them. In general, I think there are two main strategies when choosing a GPU: Either use RTX 20 series GPUs to achieve rapid upgrades, or use cheap GTX 10 series GPUs and upgrade after RTX Titan is launched. If performance is not that important, or if high performance is not required at all, such as Kaggle data competitions, startups, prototyping or learning deep learning, then the relatively inexpensive GTX 10 series GPU is also a good choice. If you choose the GTX 10 series GPU, please make sure that the GPU memory size can meet your requirements.
So for deep learning, how to choose GPU? My suggestions are as follows:
Overall, the best GPU is: RTX 2080 Ti
Cost-effective, but expensive: RTX 2080, GTX 1080
Cost-effective and affordable: GTX 1070, GTX 1070 Ti, GTX 1060
The data set I use> 250GB: RTX 2080 Ti or RTX 2080
I don't have much budget: GTX 1060 (6GB)
I am poor: GTX 1050 Ti (4GB) or CPU (prototyping) + AWS/TPU (training)
I participate in the Kaggle competition: GTX 1060 (6GB) for prototyping, AWS for final training; use fastai library
I am a computer vision researcher: RTX 2080 Ti; I can upgrade to RTX Titan in 2019
I am a researcher: RTX 2080 Ti or GTX 10XX -> RTX Titan (look at the storage requirements of your current model)
I want to build a GPU cluster: this is very complicated, you can refer to this article[1]
I have just started deep learning, and I am serious: you can start with GTX 1060 (6GB), or the cheap GTX 1070 or GTX 1070 Ti. It depends on what you want to do next (go to a startup, participate in Kaggle competitions, do research, apply deep learning), and then sell the original GPU and buy a more suitable one
Shenzhen Kate Technology Co., Ltd. , https://www.katevape.com