In this blog post, scientists from the Berkeley Artificial Intelligence Laboratory will show how deep reinforcement learning will control the flexible movements of a robotic arm. In addition, it will discuss how to use low-cost hardware, efficiently use reinforcement learning, and how to speed up learning. The following is the compilation brought by Lunzhi.
Why use a mechanical gripper?
At present, most robots on the market are controlled with simple grippers, which is sufficient for factories. However, for unstructured, human-centric environments (such as homes), a multi-tasking manipulator is very important. The multi-fingered manipulator is one of the most common manipulators. It can perform a variety of actions in daily life, such as moving objects, opening doors, typing, and painting.

However, it is very difficult to control a flexible manipulator. Among them, sophisticated sensors and drivers make the price of advanced manipulators very high. The emergence of deep reinforcement learning can realize automatic control of complex tasks on cheap hardware, but many deep reinforcement learning applications require a large amount of simulation data, which makes them very complicated in cost and installation. Humans can learn various actions quickly without requiring a large number of action examples. We will first show how deep reinforcement learning is used to learn complex manipulation behaviors through training in the real world, without any models or simulators, and using inexpensive robot hardware. Later, we will show how to add additional monitoring mechanisms, including demonstrations and simulations, to speed up the learning time. We are learning on two hardware platforms: one is a simple manipulator with three fingers, and the price is less than US$2500. The other is the advanced Allegro manipulator, which is priced at $15,000.

Model-free reinforcement learning in reality
The deep reinforcement learning algorithm learns through trial and error, and maximizes the reward function from experience. We will use a valve rotation task as a demonstration, the valve or faucet must be rotated 180° to open.

The reward function is just the negative distance between the current valve direction and the target position, and the robot arm must think about how to move and rotate by itself. The central problem of deep reinforcement learning is how to use weak reward signals to find complex and coordinated behavioral strategies that can make the task successful. This strategy is represented by a multi-layer neural network, which usually requires a lot of experiments. Due to the large number, professionals in the field are discussing whether deep reinforcement learning methods can be used for training outside of simulation. However, this imposes many limitations on the usability of the model: direct learning in the real environment can learn any task from experience, but using a simulator requires designing suitable examples, modeling tasks and robots, and carefully Adjust their parameters to achieve good results. First, we will prove that existing reinforcement learning algorithms can directly learn this task directly on real hardware.
We use Truncated Natural Policy Gradient to learn this task, which takes about 9 hours on real hardware.

The direct reinforcement learning method is very attractive, it does not require too many assumptions, and it can automatically master many skills. Since this method does not require other information besides the establishment of the function, it is easy to relearn skills in an improved environment, such as replacing the target object or manipulator.
The following figure uses different materials (sponges), and the same method can be used to let the manipulator learn to rotate the valve. If you use the simulation method, it is difficult to learn accurately, and training directly in reality does not require accurate demonstration.

Another task was to flip the board 180° on the horizontal plane. It took 8 hours to solve this problem without a simulation case.


These behaviors were implemented on a device for less than $2,500, plus a custom desktop computer.
Use human demonstrations to accelerate learning
Reinforcement learning without a model can be very versatile, but if human experts add supervision to it, it will be more helpful to accelerate the learning speed. The specific method can refer to our paper Demonstration Augmented Policy Gradient (DAPG). The idea behind DAPG is that human demonstration can accelerate reinforcement learning in two ways:
Provide a good initial state for the strategy through behavioral cloning
Add auxiliary learning signals in the learning process and use auxiliary rewards to guide research and exploration
The auxiliary goals in reinforcement learning can prevent the strategy from deviating from the demonstration during the reinforcement learning process. The pure behavior of cloning with limited data usually fails to train a successful strategy because of distribution bias and limited data support. Reinforcement learning is very important for robustness and generalization, and the use of demonstration can indeed speed up the learning process. The following figure shows the verification we made on different tasks:
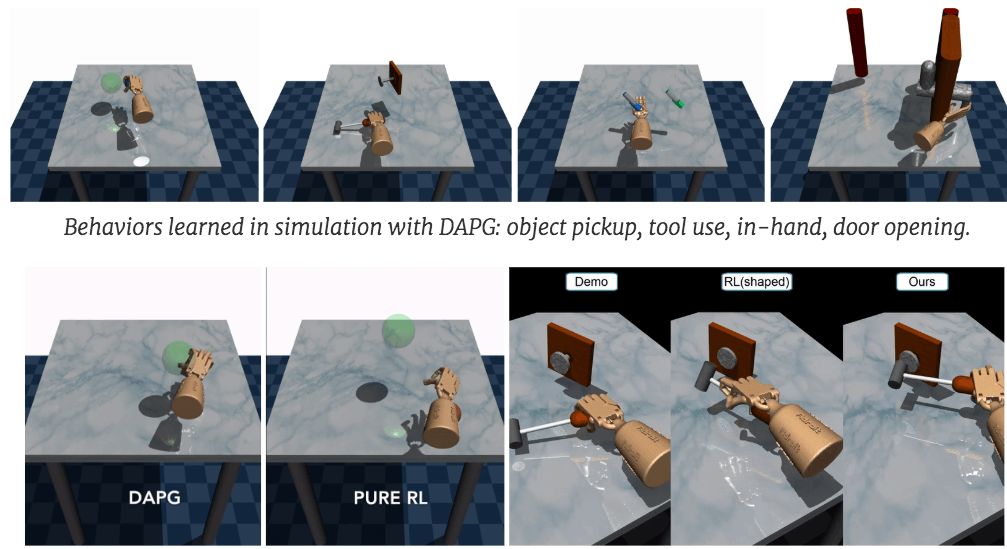
In the real world, we can use grippers and algorithms with multi-functional sensors to significantly speed up learning. In the example below, the human teacher directly moved the finger of the robot, and as a result, the training time was reduced to less than 4 hours.
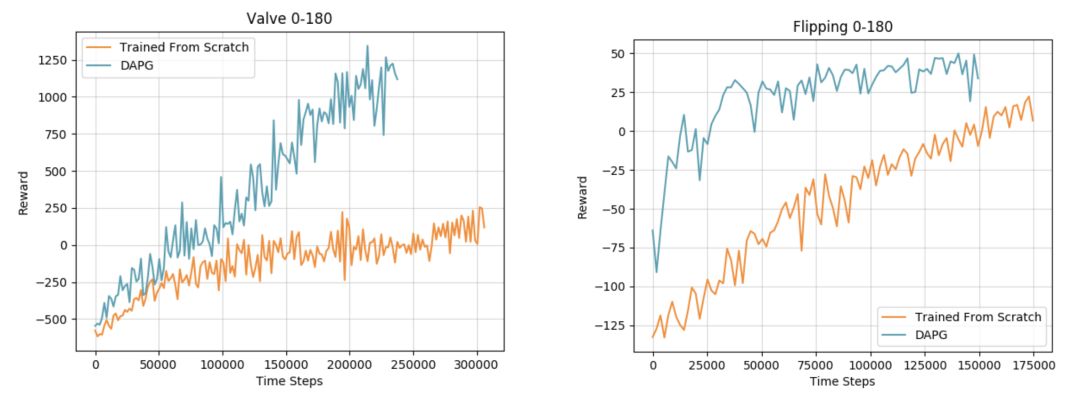
The demonstration combines human prior knowledge into the algorithm in a natural way and accelerates the learning process. However, not all tasks can be accelerated by demonstration, and we need to find other alternative acceleration methods.
Accelerate learning through imitation
The simulation model of a certain task can enhance the display data through a large amount of simulation data. For the data to represent the complexity of the real world, it is usually necessary to randomly select a variety of simulation parameters. Previous studies have proved that such random results can help generate a stable strategy that can be used for face migration. Our experiments have also proved that the migration from simulation to reality with random data is very effective.

Although migration through randomization is a good choice for fragile robots, this method has several drawbacks. First, because it is random, the final strategy will be too conservative. In addition, the choice of parameters is also an important point to produce good results. Good results in one field may not be transferred to other fields. Third, adding a large number of random results to a complex model will greatly increase the training time. Need more calculations. Finally, and perhaps the most important point, an accurate simulator must be built manually, and manual adjustments are required for each new task, which takes a lot of time.
Accelerate learning with learned models
Previously, we also studied how the learned dynamic model accelerates real-world reinforcement learning without the need to manually adjust the simulator. In this way, the local derivative in the dynamic model can be calculated approximately, and the local iterative optimization strategy can be carried out. This method can obtain a variety of readily available control strategies from reality. In addition, we can see that the algorithm can also learn to control actions in the gripper of the soft robot.


However, the performance of this method is also affected by the quality of the model, and the future will be researched towards model-based reinforcement learning.
Conclusion
Although training in the real environment is common, it still has several challenges:
Due to the need for a lot of exploratory behavior, we found that the mechanical gripper quickly became hot, so it took time to pause to avoid damage.
Since the gripper has to handle multiple tasks, we need to build an automatic restart device. If you want to cancel this device in the future, you need to learn how to restart it automatically.
Reinforcement learning methods need to provide rewards, and this reward needs to be designed manually. Recently we are studying the automatic reward mechanism.
However, letting robots learn complex skills directly from the real world is the only way to create a fully versatile robot. Like human learning, robots can also acquire skills through simple trial and error. Adding demonstrations, simulators and prior knowledge at the same time can greatly reduce training time.
Maintenance Free Nickel-Cadmium Battery
Maintenance Free Nickel-Cadmium Battery
Maintenance Free Battery,low maintenance nicd battery
Henan Xintaihang Power Source Co.,Ltd , https://www.taihangbattery.com